新湖畔网 (随信APP) | OpenAI的最强竞争产品有重大更新!电脑可以像模拟人类一样用一句话,AI智能体取得了突破性进展。

文章目录[隐藏]
新湖畔网 (随信APP) | OpenAI的最强竞争产品有重大更新!电脑可以像模拟人类一样用一句话,AI智能体取得了突破性进展。
【微信/公众号/视频号/抖音/小红书/快手/bilibili/微博/知乎/今日头条同步报道】
OpenAI一直在慢悠悠地推出新版本。
在整个宇宙中,能与OpenAI抗衡的对手寥寥可数,Anthropic旗下的Claude模型算是一个靠谱的对手。
虽然没有等到“超大杯”Opus的亮相,但好在等来了全新升级的大杯Claude 3.5 Sonnet。
这次更新的亮点:
- 拳打GPT-4o,脚踢Gemini 1.5 Pro,新版Claude 3.5 Sonnet表现遥遥领先
- Claude 3.5 Haiku响应速度最快,性能媲美GPT-4o mini
- 构建API,教Claude怎么玩电脑
教Claude玩电脑,AI键盘侠来了?
这次更新的重点其实是如何教AI玩电脑。
Anthropic推出了一个公开测试的革命性功能“computer use”:通过API教Claude像个人一样操作电脑,能看屏幕、动光标、点按钮、打字……
简单总结就是,现在Claude能用人类设计的标准工具和软件了。开发者可以借此解放一些枯燥的重复流程任务,甚至进行开放式任务,如研究。

为了让Claude具备这种技能,Anthropic通过API让Claude能感知并与计算机界面交互。
开发者在交互过程中集成这一API,让Claude将指令翻译成计算机指令,比如完成任务。
测试平台OSWorld用于评估AI模型在真实计算机环境中执行开放式任务的能力。
在仅用截图的测试中,Claude 3.5 Sonnet得分14.9%,领先第二名的7.8%。允许更多步骤时,得分为22.0%。
一些公司已经开始利用这一功能。
例如,Replit利用Claude 3.5 Sonnet的计算机操作与界面导航能力,为其智能体产品开发关键功能。
然而,这一功能仍处于实验阶段,速度较慢,且经常出现错误。一些简单操作对Claude来说仍是挑战。
在录制演示时,Claude不小心终止了一个长时间屏幕录制,结果录像素材丢失。
之后,Claude在编码演示间隙休息,开始欣赏黄石国家公园的照片。
此外,Claude通过截取屏幕图像理解屏幕上发生的事情,但可能无法捕捉短暂动作或通知。
预计这功能会逐渐改进。
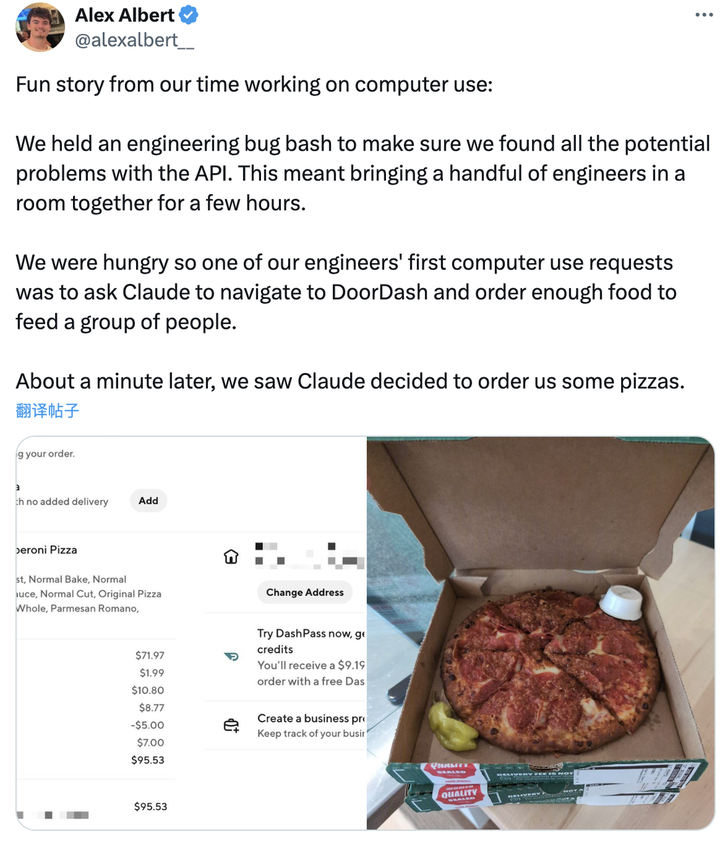
Anthropic开发者关系主管分享了一个有趣经历。
在工程故障排查会上,一位工程师请求Claude订购食物,Claude最后订了几份披萨。
拒绝服务的清单:
- 在社交媒体或其他平台上创建账户
- 发送电子邮件或消息
- 在社交媒体上发布评论
- 进行购买
- 访问私人信息
- 完成验证码(CAPTCHA)
- 生成、编辑或修改图片
- 打电话
- 访问受限内容
- 执行需要个人身份验证的操作

新模型表现突出
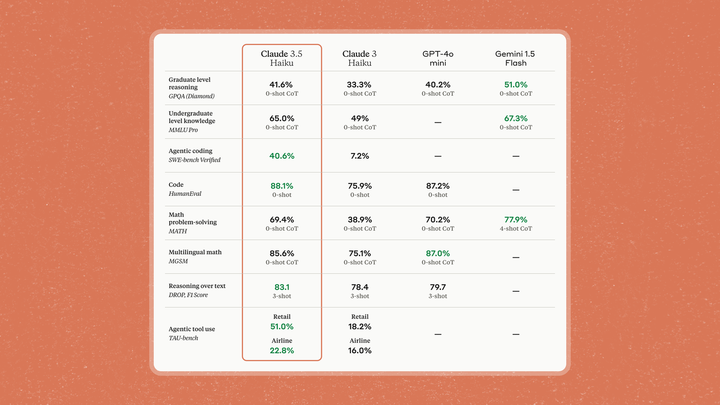
Claude 3.5 Sonnet在基准测试中表现亮眼,特别在编码领域领先。
在SWE-bench Verified的测试中,其得分从33.4%提升到49.0%,超过了所有公开模型。
Claude 3.5 Sonnet是真正的推理模型之王。
继续看看全新升级模型Claude 3.5 Haiku。
在编码任务中表现突出,得分为40.6%,超过许多智能体。
低延迟、指令执行能力改进以及精准的工具使用让Claude 3.5 Haiku适用于个性化服务场景。
升级版的Claude 3.5 Sonnet已于前段时间开放,而Claude 3.5 Haiku将于本月晚些时候发布。

未来几年AGI将实现,各方宣称,但产品才是真正的证明。
随着产品发布节奏,《OpenAI》也即将出手,下一个可能是OpenAI o1或Sora。
让我们拭目以待,看看OpenAI的下一步举措。
#OpenAI #最强竞品大更新一句话模拟人类用电脑AI #智能体觉醒前的重大突破 #爱范儿
英文版:
It's been a struggle with OpenAI for a long time.
Looking around, there are few opponents who can compete with OpenAI, and the Claude model under Anthropic is at least a reliable rival.
We hoped for the debut of the "super-sized" Opus model, but fortunately we also got the all-new upgraded big cup Claude 3.5 Sonnet.
To summarize the highlights of this update:
- Claude 3.5 Sonnet outperforms GPT-4o and Gemini 1.5 Pro
- Claude 3.5 Haiku has the fastest response time, comparable to GPT-4o mini
- Building an API to teach Claude how to use a computer
Teaching Claude to Use a Computer: Is AI Becoming a Keyboard Warrior?
The highlight of this update is not a new model, but rather how to teach AI to use a computer.
Anthropic has introduced a revolutionary feature called "computer use" for public testing: through an API, teach Claude to operate a computer like a human – see screen, move cursor, click buttons, type...
In simple terms, Claude can now use standard human-designed tools and software. Developers can use this to automate repetitive tasks and even perform open-ended tasks like research.
To give Claude this ability, Anthropic uses an API to enable Claude to perceive and interact with computer interfaces.
Developers integrate this API into interactions to translate instructions (e.g., "Fill out a form using data on my computer and information online") into computer commands (e.g., check form, move mouse to open a browser, navigate to relevant webpage, and fill form with online data).
OSWorld is a benchmark platform for testing multimodal agents' ability to perform open-ended tasks in a real computer environment, typically used to assess whether AI models can use computers like humans.
In the screenshot-only testing category, Claude 3.5 Sonnet scored 14.9%, far ahead of the runner-up at 7.8%. With more allowed steps, Claude's score is 22.0%.
Some companies are already using this functionality.
For example, Replit is leveraging Claude 3.5 Sonnet's computer operations and interface navigation abilities to develop a critical feature for its Replit Intelligence product, which will help in evaluating their developing applications.
Of course, this approach is not new.
Prior to this, Asana, Canva, Cognition, DoorDash, Replit, and The Browser Company had already begun exploring these possibilities for executing tasks that require dozens or even hundreds of steps.
However, reality is not as ideal as it seems.
Officially, the current functionality is still in the experimental stage, with slow speeds and frequent errors when operating the computer. Some seemingly simple operations, such as scrolling, dragging, zooming – tasks that seem trivial to humans – are still major challenges for Claude.
During the recording of these demos, we encountered some interesting episodes. One time, Claude accidentally terminated a long screen recording in progress, resulting in the loss of all video materials.
Later, Claude took a break from our coding demo and began admiring photos of Yellowstone National Park.
Additionally, Claude captures static images of the screen and combines them to understand what's happening on the screen. However, this means that it may miss out on brief actions or notifications on the screen, such as pop-up windows or rapidly changing icons.
Officially, the release of an experimental product is to gather feedback from developers, with expectations for gradual improvements over time.
During the development of the "computer use" feature, Anthropic organized an engineering troubleshooting meeting to identify potential issues in the API.
A few engineers gathered in a room and worked for hours before getting hungry, so one engineer's first "computer use" request for Claude was to navigate to the food delivery platform DoorDash and order enough food to feed everyone.
After about a minute of thought, Claude finally ordered several pizzas for the engineers.
Users quickly discovered a list of tasks that the computer use feature refuses to do:
- Create accounts on social media or other platforms
- Send emails or messages
- Post comments on social media
- Make purchases
- Access personal information
- Complete CAPTCHAs
- Generate, edit, or modify images
- Make phone calls
- Access restricted content
- Perform operations requiring personal authentication
The True King of Reasoning Models: New Model Encoding Leads by Far
Let's take a look at the report card handed in by Claude 3.5 Sonnet.
Although the credibility of large model lists is not what it used to be, based on the same set of questions, we can still get a preliminary understanding of the newly released models.
Claude 3.5 Sonnet outperforms GPT-4o and Gemini 1.5 Pro in benchmarks such as GPQA, MMLU Pro, and HumanEVal, leading by a wide margin.
Especially in the encoding field, Claude 3.5 Sonnet has further widened its lead. Perhaps you may wonder why there is no comparison with the OpenAI o1 models in the benchmark tests.
The official explanation is:
The reason our evaluation sheet does not include the OpenAI o1 model series is because they require a lot of computation time before responding, unlike most models. This fundamental difference makes performance comparisons complex.
In short, we want to compare but it's not easy to compare.
However, in the SWE-bench Verified encoding tests, Claude 3.5 Sonnet's performance has increased from 33.4% to 49.0%, surpassing all publicly available models – including reasoning models like OpenAI o1-preview and various intelligent agent encoding systems.
Claude 3.5 Sonnet is the true king of reasoning models.
Additionally, in the TAU-bench intelligent agent tool tests, Claude 3.5 Sonnet also performs well.
TAU-bench primarily provides an evaluation environment closer to real-world application scenarios.
Facing retail issues, Claude 3.5 Sonnet's score has improved from 62.6% to 69.2%, and in aviation issues, its score has risen from 36.0% to 46.0%.

More importantly, these improvements have not increased the price or decreased the speed; Claude 3.5 Sonnet still maintains the same performance-to-price ratio as its predecessor.
The official blog mentions that the most significant highlight of Claude 3.5 Sonnet is the improvement in encoding ability.
GitLab tests found a 10% improvement in its reasoning ability with no additional delay, making it suitable for multi-step software development processes. The Browser Company also noted that Claude 3.5 Sonnet's performance in automating web workflows surpassed all previously tested models.
As a model company striving for high security, Anthropic naturally conducted a catastrophic risk assessment on Claude 3.5 Sonnet, which meets ASL-2 standards.
ASL-2 refers to systems that show early signs of dangerous capabilities (such as instructions on how to create biological weapons) but this information is of little use due to insufficient reliability or being unable to surpass what search engines can provide.
In short, Claude 3.5 Sonnet is strong, but not yet a threat to humanity.
After discussing the most powerful model, next up is the new upgraded model with the fastest response time – Claude 3.5 Haiku.
Looking at the specifications alone, the medium-sized Claude 3.5 Haiku is almost on par with GPT-4o mini; it can even be said that it can edge out a win and perform just as well as the previous generation Claude 3 Opus.
But with no price increase, no decrease in response time, it gives a sense of a "more for the same" experience.
Similarly, Claude 3.5 Haiku excels in encoding tasks. For example, it scored 40.6% on SWE-bench Verified, surpassing many so-called state-of-the-art intelligent agents, including its original Claude 3.5 Sonnet and GPT-4o.
Low latency, improved command execution capability, and more precise tool usage make Claude 3.5 Haiku particularly suitable for personalized service scenarios.
For example, recommending products based on your past buying habits, helping decide product prices, or managing inventory in your warehouse.
Finally, the upgraded version of Claude 3.5 Sonnet is now available to all users. Claude 3.5 Haiku will be released later this month, initially supporting text input with image input functionality to follow.
If you've been following the AI industry recently, you'll notice that several key figures in the industry have started playing the "clairvoyant" game.
Demis Hassabis, Yann LeCun, Sam Altman, and Anthropic's Dario Amodei have all claimed that AGI will be achieved in the next few years, with timelines ranging from 2025 to 2030.
They have drawn utopian blueprints for AGI that encompass curing most diseases, solving climate issues, eradicating poverty, etc., making AI seem like a panacea for all ills.
However, confidence needs to be backed by real-world products.
Without a reliable, sustainable business model, the industry can only sustain high investments and expenses through "blind faith" in AGI, like a dangling carrot in front of a donkey.
In other words, the products like the Claude model released today are also aimed at restoring our confidence, and following their usual product launch schedule, OpenAI is expected to make a move soon.
The difference is that OpenAI's arsenal is clearly more extensive. Perhaps the next unveiling will be the official version of OpenAI o1, or maybe the "futures" model Sora.
Let's wait and see how OpenAI wields its sword next.
OpenAI 最强竞品大更新!一句话模拟人类用电脑,AI 智能体觉醒前的重大突破 | 爱范儿
#OpenAI #最强竞品大更新一句话模拟人类用电脑AI #智能体觉醒前的重大突破 #爱范儿
关注流程:打开随信App→搜索新湖畔网随信号:973641 →订阅即可!
公众号:新湖畔网 抖音:新湖畔网
视频号:新湖畔网 快手:新湖畔网
小红书:新湖畔网 随信:新湖畔网
百家号:新湖畔网 B站:新湖畔网
知乎:新湖畔网 微博:新湖畔网
UC头条:新湖畔网 搜狐号:新湖畔网
趣头条:新湖畔网 虎嗅:新湖畔网
腾讯新闻:新湖畔网 网易号:新湖畔网
36氪:新湖畔网 钛媒体:新湖畔网
今日头条:新湖畔网 西瓜视频:新湖畔网



